
公司动态
出乎意料的是,新的最开放的模型来自Xiaohongsh
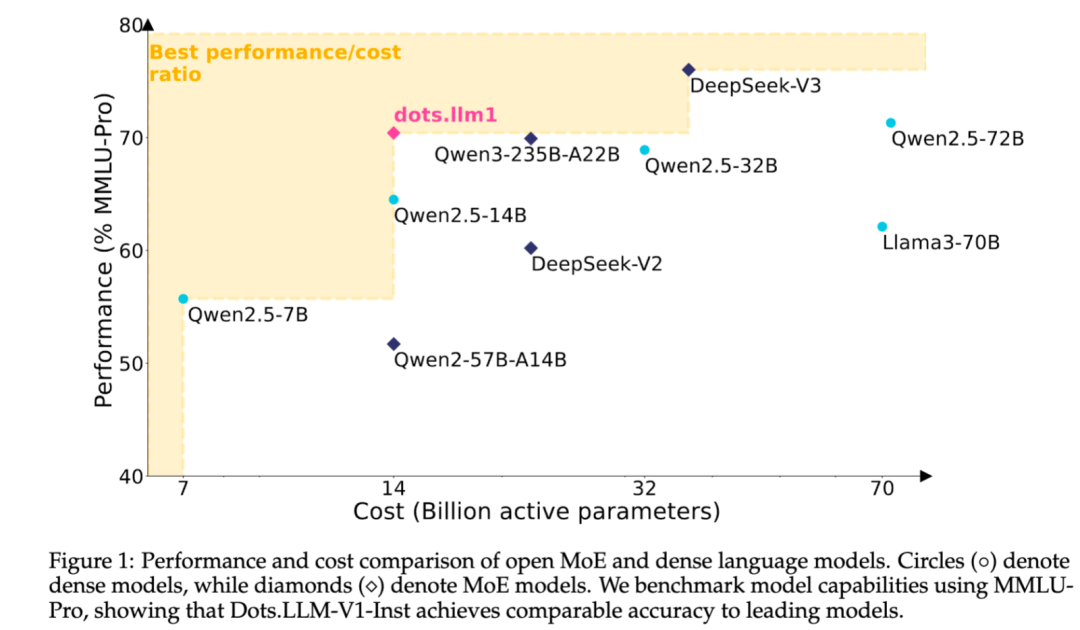 机器中心编辑:Yang Wen迄今为止最大的开源单元。小舒一直以出色的模型谦虚,但昨天我们推出了第一个出色的自我开发模型。该模型称为dots.llm1,是Xiaohongshu Hi Lab(人类智能实验室)开发的文本模型。该参数不是最大值,参数的总体积为142B,激活参数为14B。这是一个中等大小的MOE(混合专家)模型,但仍然具有较小的激活功能的表现出色。具体而言,随着参数14b的激活,dots.llm.inm.inst Model在中文和英语方案,数学,代码和对齐任务中效果很好,并且与QWEN2.5-32B-INSTRUCT和QWEN2.5-72B教学相比,竞争性高。同时,与qwen3-32b相比,它在中文,英语,数学和alineation中的工作方式相似。此外,可以说这是开源力模型是行业屋顶的“体积”。该型号不仅可用于在框外使用它们的开发人员使用,而且实验室设备会想象并打开了一系列简单的模型,包括在欧林前欧林第一阶段中包含1T令牌后存储控制点的控制点,包括两个基于长文本的模型在回收期阶段进行训练。 HI Lab团队还提供了详细的信息,例如LR计划和批次大小,以鼓励所有人继续进行预先进行和监督的调整。从头到尾,几乎所有细节都可以用作“第二创建”。自2023年以来,小苏开始投资基本模型的研究和开发,而这一开源是积极参与与技术社区对话的重要一步。型号地址:https://huggingface.co/rednote-hilab https://github.com/ rednote-hilab/dots.llm1真实的真实测试模型的易用性LSO取决于多维任务的真实证明的性能。接下来,我们将将小舒的点模型带到“考试室”,我们将对问题和答案,写作,编码等进行整体评估。首先,让我们证明其了解中国的能力。第九叔叔借给他的第十叔叔,达到了他的第十一叔叔1,000元的薪水。谁是小偷?这个问题就像龙卷风龙卷风,但要点并不困惑。它逐渐被分解并分析句子的结构,以找到“偷窃”行为的衰落,并最终提供了正确的句子。回答。 Smart Bar以其幽默和荒谬的笑话而闻名。从伟大的“智能酒吧”的普及起,已经成为检测理解伟大模型能力的标准之一。例如,这个经典的问题:教室也被称为监狱牢房,但是当您上班时,为什么不称他们为监狱呢?第一点给出SE基于语言的历史演变和两者之间的差异,然后播放模因并附加表情符号。不仅如此,还了解那些陌生人的同性恋者。让我们看一下Dots的文字写作技巧。我写了一首隐藏的诗:“我今天要上班。”这是非常“活着的”,并在早晨使用一组早期照片来描绘“工人”的非常现实的代表。此外,它具有非常好的编码功能,因此我要求他们创建使用HTML,CSS和JavaScript实施的敏感城市气象卡组件。收到任务后,请在不说话的情况下dot generathe代码。应该说,他们制作的动态卡非常舒适,并收集了几个因素,例如城市,日期,气候,温度,湿度,风速等。您也可以单击右下角的按钮以更改而没有城市之间的问题。技术解释:“与小事一起尝试”在高效的Moe架构下,是Xiaohongshu HI实验室的第一个开源MOE模型。链接:https:// github.com/rednote-hilab/dots.llm1/blob/main/dots1_tech_report.pdf Pretal Data:它们可以“几乎被迫”而无需合成。在大型模型的训练中,数据的质量是决定模型上限的关键因素之一。 dots.llm1在培训之前使用高质量的11.2T代币数据,主要源自其自己的蜘蛛捕获的常见数据和Web数据。与许多直接使用粗晶粒数据的open源模型不同,HI Lab设备通过数据处理控制数据质量,拒绝低质量或虚拟内容以及三个“过程”时,“真正的”设备非常“真正”。首先,使用优化的设备PACT,最终使用优化的Traphilac软件包,使用HTML Web数据通过URL过滤HTML Web数据。恢复MD5 Web文档的推荐。以下是介绍规则的处理E Minhash和线路级别的重复数据删除策略,以有效过滤噪声文本,例如导航广告和条,指的是用于清洁和数据过滤的复杂措施和Gopher方案。最后,使用模型的处理来共同确定数据通过多个模型的类型,质量,语义重复和结构平衡,并确保文本是安全而精确的,同时增加知识内容的百分比以确保其含义。在先前的处理过程之后,HI实验室团队获得了高质量的前数据,并通过手动验证和实验验证了数据的质量明显好于开源数据TXT360。值得注意的是,dots.llm1不使用合成语料库。这间接地表明,即使大型数据综合不取决于大规模数据,也可以训练足够强大的文本模型。但是,团队还说这是一个重要的方向将来探索是一种改善数据多样性和建模功能的方式。培训效率:计算机科学和沟通非常平行,我在这里。在MOE模型培训过程中,EP REANGIT之间的A2A通信呈现出很大的终点,这对训练效率产生了严重的影响。特别是对于精细的谷物MOE模型,EP的大小相对较大,并且交叉计算机的通信基本上是不可避免的。为了解决这一挑战,HI Lab与中国NVIDIA团队合作,提出了一种工程套装和A2A重叠的创新解决方案。该解决方案的核心是使EP A2A通信尽可能地进行,计算重叠,使用计算来覆盖通信时间并提高训练效率。具体而言,通过在固定状态1f1b阶段的第一个微键率的FPROP中前进,我们在1之前实施了1F1B投资之间的EP A2AF1B静止状态,导致1F1B投资之间的重叠。也就是说,变暖步骤 +1。以固定块大小组织M_I(专家令牌I)。该固定的块大小必须是MMNNKK镶嵌形式的M的整个倍数,这是异步组级矩阵的乘法和添加(即WGMMA,即WGMMA.MMA async)的繁殖的。该设计要求单线块中的所有战争组都采用统一的马赛克,并且子过程块处理的整个令牌段(MI)必须属于同一专家。实际测试之后,与NVIDIA Transformer发动机分组的API GEMM相比,HI LAB实施的操作员在直接计算中实施的运算符增加了14.00%,反向计算中的运营商增加了6.68%。它完全证明了该解决方案的有效性和实际价值。模型的设计和培训:在模型设计级别的WSD编程下进行的渐进优化,dots.llm1是基于A的MOE模型解码器变压器。建筑设计生成的建筑物主要基于DeepSeek系列的思想和经验。从培训策略的角度来看,该模型使用了WSD学习率的编程方法,整个培训过程主要稳定。它可以分为两个阶段:退火的培训和优化。在稳定的训练阶段,该模型保持了3E-4的学习率,并使用10T令牌语料库进行了训练。为了提高训练效率,在此阶段,批量增加了两倍,逐渐增加64 m至128 m。整个训练过程非常稳定,没有应撤退的损失峰。然后,输入学习率的学习率,并分两个阶段对Copus令牌1.2T进行培训。其中,由于退火3e-4至3E-5,阶段1的模型的学习率降低了,推理语料库和知识类型C是改进的数据,总共训练了1T令牌。在第2阶段,MODEL的学习率从恢复的3E-5降低到1E-5,改善了数学和代码语料库与数据的关系,并培训了总计200B代币。训练之后:高质量多月的结构化培训策略,在完成了先前的高质量培训后,dots.llm1甚至通过两个阶段的监督和精细调整来完善对模型的理解和执行。 HI Lab团队仔细检查了大约400,000个高质量的指导数据,其中涵盖了五个中心场景,其中包括多轮对话,问题和知识答案,监视复杂说明,数学推断和代码生成。通过内部标记的多个对话质量,并使用教师模型来优化低质量的响应,以提高一般对话的一致性和精度。问题和知识的模块答案:引入了一组数据,其中包含基于事实和阅读综合的知识Hension,这使模型可以理解并回答更好的几个知识问题。复杂的说明合规性循环:设备具有特殊设计的指令数据,并具有条件限制和不遵循限制的过滤响应。数学和代码字段:验证者验证调整后的数据以获得最高质量的监督信号。整个调整过程分为两个阶段。第一阶段是对数据总量进行两轮基本培训,以及过度的训练,动态学习率的调整和多个剪接的圆形对话将引入第一个版本的技术,例如“圆形对话框交界处”。第二阶段的重点是“关键进展”。对于需要最高推理功能的数学和代码等任务,团队采用了精细的调整采样策略(RFT),它们与验证设备相结合以过滤重要的样本,进一步改善模型的推理模型。评估的最终结果也很引人注目:即使只有14b参数,dots.llm1inst在中文和英语的理解,数学,代码生成,对齐和其他任务中仍然可以很好地运行,并且能够与qwen2.5-32b-构造竞争,甚至QWEN2.5-72B-- QWEN2.5-72B-INSTUCTION。比较最先进的QWEN3-32B,DOTS.LLM1。在多个任务中显示出相似甚至更强的性能。结论在流行的Open Huggingface源模型中,中国模型代表了市场的一半,开源逐渐成为中国型号主要团队中的集体共识。 dots.llm1的开源不仅是小米HI实验室团队的技术成就的代表,而且与封闭的房间实践相比,选择路线的选择“宣言”,这使得它愿意进入世界并与专家进行交流。在EYES开发人员,这意味着另一个可靠的模型基础。此外,对于HI实验室,社区调整转向基本模型,将更多的可能性注入模型。
机器中心编辑:Yang Wen迄今为止最大的开源单元。小舒一直以出色的模型谦虚,但昨天我们推出了第一个出色的自我开发模型。该模型称为dots.llm1,是Xiaohongshu Hi Lab(人类智能实验室)开发的文本模型。该参数不是最大值,参数的总体积为142B,激活参数为14B。这是一个中等大小的MOE(混合专家)模型,但仍然具有较小的激活功能的表现出色。具体而言,随着参数14b的激活,dots.llm.inm.inst Model在中文和英语方案,数学,代码和对齐任务中效果很好,并且与QWEN2.5-32B-INSTRUCT和QWEN2.5-72B教学相比,竞争性高。同时,与qwen3-32b相比,它在中文,英语,数学和alineation中的工作方式相似。此外,可以说这是开源力模型是行业屋顶的“体积”。该型号不仅可用于在框外使用它们的开发人员使用,而且实验室设备会想象并打开了一系列简单的模型,包括在欧林前欧林第一阶段中包含1T令牌后存储控制点的控制点,包括两个基于长文本的模型在回收期阶段进行训练。 HI Lab团队还提供了详细的信息,例如LR计划和批次大小,以鼓励所有人继续进行预先进行和监督的调整。从头到尾,几乎所有细节都可以用作“第二创建”。自2023年以来,小苏开始投资基本模型的研究和开发,而这一开源是积极参与与技术社区对话的重要一步。型号地址:https://huggingface.co/rednote-hilab https://github.com/ rednote-hilab/dots.llm1真实的真实测试模型的易用性LSO取决于多维任务的真实证明的性能。接下来,我们将将小舒的点模型带到“考试室”,我们将对问题和答案,写作,编码等进行整体评估。首先,让我们证明其了解中国的能力。第九叔叔借给他的第十叔叔,达到了他的第十一叔叔1,000元的薪水。谁是小偷?这个问题就像龙卷风龙卷风,但要点并不困惑。它逐渐被分解并分析句子的结构,以找到“偷窃”行为的衰落,并最终提供了正确的句子。回答。 Smart Bar以其幽默和荒谬的笑话而闻名。从伟大的“智能酒吧”的普及起,已经成为检测理解伟大模型能力的标准之一。例如,这个经典的问题:教室也被称为监狱牢房,但是当您上班时,为什么不称他们为监狱呢?第一点给出SE基于语言的历史演变和两者之间的差异,然后播放模因并附加表情符号。不仅如此,还了解那些陌生人的同性恋者。让我们看一下Dots的文字写作技巧。我写了一首隐藏的诗:“我今天要上班。”这是非常“活着的”,并在早晨使用一组早期照片来描绘“工人”的非常现实的代表。此外,它具有非常好的编码功能,因此我要求他们创建使用HTML,CSS和JavaScript实施的敏感城市气象卡组件。收到任务后,请在不说话的情况下dot generathe代码。应该说,他们制作的动态卡非常舒适,并收集了几个因素,例如城市,日期,气候,温度,湿度,风速等。您也可以单击右下角的按钮以更改而没有城市之间的问题。技术解释:“与小事一起尝试”在高效的Moe架构下,是Xiaohongshu HI实验室的第一个开源MOE模型。链接:https:// github.com/rednote-hilab/dots.llm1/blob/main/dots1_tech_report.pdf Pretal Data:它们可以“几乎被迫”而无需合成。在大型模型的训练中,数据的质量是决定模型上限的关键因素之一。 dots.llm1在培训之前使用高质量的11.2T代币数据,主要源自其自己的蜘蛛捕获的常见数据和Web数据。与许多直接使用粗晶粒数据的open源模型不同,HI Lab设备通过数据处理控制数据质量,拒绝低质量或虚拟内容以及三个“过程”时,“真正的”设备非常“真正”。首先,使用优化的设备PACT,最终使用优化的Traphilac软件包,使用HTML Web数据通过URL过滤HTML Web数据。恢复MD5 Web文档的推荐。以下是介绍规则的处理E Minhash和线路级别的重复数据删除策略,以有效过滤噪声文本,例如导航广告和条,指的是用于清洁和数据过滤的复杂措施和Gopher方案。最后,使用模型的处理来共同确定数据通过多个模型的类型,质量,语义重复和结构平衡,并确保文本是安全而精确的,同时增加知识内容的百分比以确保其含义。在先前的处理过程之后,HI实验室团队获得了高质量的前数据,并通过手动验证和实验验证了数据的质量明显好于开源数据TXT360。值得注意的是,dots.llm1不使用合成语料库。这间接地表明,即使大型数据综合不取决于大规模数据,也可以训练足够强大的文本模型。但是,团队还说这是一个重要的方向将来探索是一种改善数据多样性和建模功能的方式。培训效率:计算机科学和沟通非常平行,我在这里。在MOE模型培训过程中,EP REANGIT之间的A2A通信呈现出很大的终点,这对训练效率产生了严重的影响。特别是对于精细的谷物MOE模型,EP的大小相对较大,并且交叉计算机的通信基本上是不可避免的。为了解决这一挑战,HI Lab与中国NVIDIA团队合作,提出了一种工程套装和A2A重叠的创新解决方案。该解决方案的核心是使EP A2A通信尽可能地进行,计算重叠,使用计算来覆盖通信时间并提高训练效率。具体而言,通过在固定状态1f1b阶段的第一个微键率的FPROP中前进,我们在1之前实施了1F1B投资之间的EP A2AF1B静止状态,导致1F1B投资之间的重叠。也就是说,变暖步骤 +1。以固定块大小组织M_I(专家令牌I)。该固定的块大小必须是MMNNKK镶嵌形式的M的整个倍数,这是异步组级矩阵的乘法和添加(即WGMMA,即WGMMA.MMA async)的繁殖的。该设计要求单线块中的所有战争组都采用统一的马赛克,并且子过程块处理的整个令牌段(MI)必须属于同一专家。实际测试之后,与NVIDIA Transformer发动机分组的API GEMM相比,HI LAB实施的操作员在直接计算中实施的运算符增加了14.00%,反向计算中的运营商增加了6.68%。它完全证明了该解决方案的有效性和实际价值。模型的设计和培训:在模型设计级别的WSD编程下进行的渐进优化,dots.llm1是基于A的MOE模型解码器变压器。建筑设计生成的建筑物主要基于DeepSeek系列的思想和经验。从培训策略的角度来看,该模型使用了WSD学习率的编程方法,整个培训过程主要稳定。它可以分为两个阶段:退火的培训和优化。在稳定的训练阶段,该模型保持了3E-4的学习率,并使用10T令牌语料库进行了训练。为了提高训练效率,在此阶段,批量增加了两倍,逐渐增加64 m至128 m。整个训练过程非常稳定,没有应撤退的损失峰。然后,输入学习率的学习率,并分两个阶段对Copus令牌1.2T进行培训。其中,由于退火3e-4至3E-5,阶段1的模型的学习率降低了,推理语料库和知识类型C是改进的数据,总共训练了1T令牌。在第2阶段,MODEL的学习率从恢复的3E-5降低到1E-5,改善了数学和代码语料库与数据的关系,并培训了总计200B代币。训练之后:高质量多月的结构化培训策略,在完成了先前的高质量培训后,dots.llm1甚至通过两个阶段的监督和精细调整来完善对模型的理解和执行。 HI Lab团队仔细检查了大约400,000个高质量的指导数据,其中涵盖了五个中心场景,其中包括多轮对话,问题和知识答案,监视复杂说明,数学推断和代码生成。通过内部标记的多个对话质量,并使用教师模型来优化低质量的响应,以提高一般对话的一致性和精度。问题和知识的模块答案:引入了一组数据,其中包含基于事实和阅读综合的知识Hension,这使模型可以理解并回答更好的几个知识问题。复杂的说明合规性循环:设备具有特殊设计的指令数据,并具有条件限制和不遵循限制的过滤响应。数学和代码字段:验证者验证调整后的数据以获得最高质量的监督信号。整个调整过程分为两个阶段。第一阶段是对数据总量进行两轮基本培训,以及过度的训练,动态学习率的调整和多个剪接的圆形对话将引入第一个版本的技术,例如“圆形对话框交界处”。第二阶段的重点是“关键进展”。对于需要最高推理功能的数学和代码等任务,团队采用了精细的调整采样策略(RFT),它们与验证设备相结合以过滤重要的样本,进一步改善模型的推理模型。评估的最终结果也很引人注目:即使只有14b参数,dots.llm1inst在中文和英语的理解,数学,代码生成,对齐和其他任务中仍然可以很好地运行,并且能够与qwen2.5-32b-构造竞争,甚至QWEN2.5-72B-- QWEN2.5-72B-INSTUCTION。比较最先进的QWEN3-32B,DOTS.LLM1。在多个任务中显示出相似甚至更强的性能。结论在流行的Open Huggingface源模型中,中国模型代表了市场的一半,开源逐渐成为中国型号主要团队中的集体共识。 dots.llm1的开源不仅是小米HI实验室团队的技术成就的代表,而且与封闭的房间实践相比,选择路线的选择“宣言”,这使得它愿意进入世界并与专家进行交流。在EYES开发人员,这意味着另一个可靠的模型基础。此外,对于HI实验室,社区调整转向基本模型,将更多的可能性注入模型。 上一篇:加拿大的商业赤字达到了最高率 下一篇:单击此处查找2025年大学入学考试!
